Stream 作为一个 lazy 的 list 最重要的就是获得一个逐渐自动生长的搜索空间,通过这个搜索空间我们可以求解多种有意思的问题。
- 优化问题的求解,在连续函数问题上,我们可以认为优化变量的取值本身构成一个状态,状态的迁移是通过诸如梯度、共轭梯度或者 Newton 法(or quasi-Newton)获得的更新量,这样当前的更新量实际可能依赖于前一个或者多个状态 or 搜索方向,我们大可以将
 作为这个 stream 的类型,而更新方程对应的就是生成这个 stream 的递归调用
作为这个 stream 的类型,而更新方程对应的就是生成这个 stream 的递归调用
- 图搜索问题,不少离散的问题最后可以归结到图上的搜索,经典的过河问题、水杯倒水和这次作业里面的游戏 Bloxorz,这类问题首先需要把实际问题通过 graph 来进行建模,也就是状态是什么,对应的操作会导致什么样的状态迁移,有了这些,加上初始状态,你就会得到或者 BFS/DFS 的搜索算法,如果你有一些 heuristic,还能改成 A* search。
我们来看看这些问题如何转换的。首先看问题:
- 过河问题:河一边若干人,一条船,一次载两人,人群里面有些 constraints,比如某两个人不能单独在某侧,问如何将这群人从一边运送到另一边
- 若干个已知总容量的杯子,可以将某些杯子倒满水,也可以倒掉,或者杯子之间互相倒,但是杯子没有刻度,问如何精确倒出指定容积的水
- bloxorz 控制 1×2 的 block,在一个网格上通过翻转滚动且避免从不应该的位置掉下去,让它移动到指定的位置(这里不考虑原游戏的桥)
第一步就是抽象出来状态和迁移的可能
- 我们可以将河两侧的人作为两个 set,另船的位置,这两者是状态;操作包括运送船从一边到另一边,船上可以上 1-2 人,合法的操作不会导致每边出现违背要求的状态
- 杯子里面有多少水作为状态,操作有三种,将某个杯子倒满/倒空,从某个杯子倒入另外一个
- 当前 block 的位置作为状态,如用两个坐标表示,操作包括各个方向的运动,对这两个坐标分别操作即可
第二步确定起始状态:
- 开始状态是人都在一边,船也在那边;结束是都到另一边
- 开始是全空,结束是某一/几个杯子的水正好是指定大小
- 开始是指定位置,结束是指定位置
一般将状态作为一个类,对应的操作可以作为其成员或者另外的方法,通常复杂的情况需要写个判断是否合法的东西,通过这些方法或者函数我们就能生成新的状态,为了回溯,我们可能还会记录这个操作序列,有了这些我们就能产生 stream 了。就不贴程序了,某作业里面要求解 bloxorz 的问题如下
ooo-------
oSoooo----
ooooooooo-
-ooooooooo
-----ooToo
------ooo-
通过 BFS 输出如下:
block: Pos(1,2), Pos(1,3), 1 moves: List(Right)
block: Pos(2,1), Pos(3,1), 1 moves: List(Down)
block: Pos(1,4), Pos(1,4), 2 moves: List(Right, Right)
block: Pos(2,2), Pos(2,3), 2 moves: List(Down, Right)
block: Pos(2,2), Pos(3,2), 2 moves: List(Right, Down)
block: Pos(2,4), Pos(3,4), 3 moves: List(Down, Right, Right)
block: Pos(2,1), Pos(2,1), 3 moves: List(Left, Down, Right)
block: Pos(2,4), Pos(2,4), 3 moves: List(Right, Down, Right)
block: Pos(3,2), Pos(3,3), 3 moves: List(Down, Down, Right)
block: Pos(2,3), Pos(3,3), 3 moves: List(Right, Right, Down)
block: Pos(1,2), Pos(1,2), 3 moves: List(Up, Right, Down)
block: Pos(2,3), Pos(3,3), 4 moves: List(Left, Down, Right, Right)
block: Pos(2,5), Pos(3,5), 4 moves: List(Right, Down, Right, Right)
block: Pos(0,1), Pos(1,1), 4 moves: List(Up, Left, Down, Right)
block: Pos(2,5), Pos(2,6), 4 moves: List(Right, Right, Down, Right)
block: Pos(3,1), Pos(3,1), 4 moves: List(Left, Down, Down, Right)
block: Pos(3,4), Pos(3,4), 4 moves: List(Right, Down, Down, Right)
block: Pos(1,3), Pos(1,3), 4 moves: List(Up, Right, Right, Down)
block: Pos(1,0), Pos(1,1), 4 moves: List(Left, Up, Right, Down)
block: Pos(1,3), Pos(1,4), 4 moves: List(Right, Up, Right, Down)
block: Pos(1,3), Pos(1,3), 5 moves: List(Up, Left, Down, Right, Right)
block: Pos(2,6), Pos(3,6), 5 moves: List(Right, Right, Down, Right, Right)
block: Pos(1,5), Pos(1,5), 5 moves: List(Up, Right, Down, Right, Right)
block: Pos(4,5), Pos(4,5), 5 moves: List(Down, Right, Down, Right, Right)
block: Pos(0,0), Pos(1,0), 5 moves: List(Left, Up, Left, Down, Right)
block: Pos(0,2), Pos(1,2), 5 moves: List(Right, Up, Left, Down, Right)
block: Pos(2,7), Pos(2,7), 5 moves: List(Right, Right, Right, Down, Right)
block: Pos(3,5), Pos(3,6), 5 moves: List(Down, Right, Right, Down, Right)
block: Pos(1,1), Pos(2,1), 5 moves: List(Up, Left, Down, Down, Right)
block: Pos(3,5), Pos(3,6), 5 moves: List(Right, Right, Down, Down, Right)
block: Pos(1,4), Pos(2,4), 5 moves: List(Up, Right, Down, Down, Right)
block: Pos(1,1), Pos(1,2), 5 moves: List(Left, Up, Right, Right, Down)
block: Pos(1,4), Pos(1,5), 5 moves: List(Right, Up, Right, Right, Down)
block: Pos(0,0), Pos(0,1), 5 moves: List(Up, Left, Up, Right, Down)
block: Pos(2,0), Pos(2,1), 5 moves: List(Down, Left, Up, Right, Down)
block: Pos(1,5), Pos(1,5), 5 moves: List(Right, Right, Up, Right, Down)
block: Pos(2,3), Pos(2,4), 5 moves: List(Down, Right, Up, Right, Down)
block: Pos(1,1), Pos(1,2), 6 moves: List(Left, Up, Left, Down, Right, Right)
block: Pos(1,4), Pos(1,5), 6 moves: List(Right, Up, Left, Down, Right, Right)
block: Pos(2,7), Pos(3,7), 6 moves: List(Right, Right, Right, Down, Right, Right)
block: Pos(4,6), Pos(4,6), 6 moves: List(Down, Right, Right, Down, Right, Right)
block: Pos(4,6), Pos(4,7), 6 moves: List(Right, Down, Right, Down, Right, Right)
block: Pos(2,0), Pos(2,0), 6 moves: List(Down, Left, Up, Left, Down, Right)
block: Pos(2,2), Pos(2,2), 6 moves: List(Down, Right, Up, Left, Down, Right)
block: Pos(3,7), Pos(4,7), 6 moves: List(Down, Right, Right, Right, Down, Right)
block: Pos(3,7), Pos(3,7), 6 moves: List(Right, Down, Right, Right, Down, Right)
block: Pos(4,5), Pos(4,6), 6 moves: List(Down, Down, Right, Right, Down, Right)
block: Pos(1,0), Pos(2,0), 6 moves: List(Left, Up, Left, Down, Down, Right)
block: Pos(1,2), Pos(2,2), 6 moves: List(Right, Up, Left, Down, Down, Right)
block: Pos(0,1), Pos(0,1), 6 moves: List(Up, Up, Left, Down, Down, Right)
block: Pos(3,7), Pos(3,7), 6 moves: List(Right, Right, Right, Down, Down, Right)
block: Pos(4,5), Pos(4,6), 6 moves: List(Down, Right, Right, Down, Down, Right)
block: Pos(1,3), Pos(2,3), 6 moves: List(Left, Up, Right, Down, Down, Right)
block: Pos(1,5), Pos(2,5), 6 moves: List(Right, Up, Right, Down, Down, Right)
block: Pos(1,0), Pos(1,0), 6 moves: List(Left, Left, Up, Right, Right, Down)
block: Pos(0,1), Pos(0,2), 6 moves: List(Up, Left, Up, Right, Right, Down)
block: Pos(2,1), Pos(2,2), 6 moves: List(Down, Left, Up, Right, Right, Down)
block: Pos(2,4), Pos(2,5), 6 moves: List(Down, Right, Up, Right, Right, Down)
block: Pos(0,2), Pos(0,2), 6 moves: List(Right, Up, Left, Up, Right, Down)
block: Pos(2,2), Pos(2,2), 6 moves: List(Right, Down, Left, Up, Right, Down)
block: Pos(2,5), Pos(2,5), 6 moves: List(Right, Down, Right, Up, Right, Down)
block: Pos(3,3), Pos(3,4), 6 moves: List(Down, Down, Right, Up, Right, Down)
block: Pos(1,0), Pos(1,0), 7 moves: List(Left, Left, Up, Left, Down, Right, Right)
block: Pos(0,1), Pos(0,2), 7 moves: List(Up, Left, Up, Left, Down, Right, Right)
block: Pos(2,1), Pos(2,2), 7 moves: List(Down, Left, Up, Left, Down, Right, Right)
block: Pos(2,4), Pos(2,5), 7 moves: List(Down, Right, Up, Left, Down, Right, Right)
block: Pos(2,8), Pos(3,8), 7 moves: List(Right, Right, Right, Right, Down, Right, Right)
block: Pos(4,7), Pos(4,7), 7 moves: List(Down, Right, Right, Right, Down, Right, Right)
List(Down, Right, Right, Right, Down, Right, Right)
其实对 C/C++/Java 程序员来说这类问题也是类似求解的,但是会更依赖于 stack/queue 这些东西,而 scala 的 functional 的这面试图通过一些规则和诡异的 lazy 结构(stream)简化这些问题求解的细节。不得不说算是另外的一种思路吧
——————
When Esau saw that Isaac had blessed Jacob, and sent him away to Padanaram, to take him a wife from thence; and that as he blessed him he gave him a charge, saying, Thou shalt not take a wife of the daughters of Canaan;



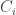

![c[n, m] = \min\{c[n - 1, m] + C_d, c[n, m-1] + C_i, c[n-1, m-1] + C_c (a_n, b_m) \}](https://s0.wp.com/latex.php?latex=c%5Bn%2C+m%5D+%3D+%5Cmin%5C%7Bc%5Bn+-+1%2C+m%5D+%2B+C_d%2C+c%5Bn%2C+m-1%5D+%2B+C_i%2C+c%5Bn-1%2C+m-1%5D+%2B+C_c+%28a_n%2C+b_m%29+%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002)








,同时比较相同长度的(k),这个可以从最长的子串(N – 1)开始做,一直到找到相同的停止,每次比较代价也是 k,所以整个的复杂度至少是立方级别
的而后面扫一遍感觉还是





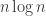


 级别的。不知道有没有更快的实现。类似的诸如
级别的。不知道有没有更快的实现。类似的诸如 