后缀树是一种非常有用的数据结构,我们虽然从这里开始讨论,后面还是有必要在合适的时候讨论 string matching 的一些其他的基本思路,作为历史发展的参考。
定义 长度为 m 的字符串对应的 suffix tree 是一个“有向的 tree”(所谓有向指跟随从 root 出发的 path):
- 每条边上有 label(字符串里面的几个字符)且从一个节点出发边的 label 没有相同的首字母;
- 每个非 root 节点至少有两个子节点;
- 它有 m 个 leaf,每条从 root 到 leaf 的 path 上所有边组成字符串对应于这个字符串的一个suffix,这样我们可以对每个 leaf 进行编号,对应着字符串从第 i 个字符开始的 suffix;
这个定义存在的问题是如果字符串的某个后缀与其另一个后缀的前缀匹配,则会出现问题:因为前者是后者的前缀,两个 suffix 会共用一个 path,这导致前者对应的不是一个 leaf。解决这个问题一般通过引入特殊字符(不在 alphabet 里面)作为字符串的终止符(比如 C/C++ 的字符串终止符为 0x00),这样前面说的情况短的 suffix 加上这个特殊字符是不可能作为另一个 suffix 的前缀的,这样比如 xabxa 里面的 xa 是 xabxa 这个后缀的前缀,加入 $ 这个终止符后 xa$ 就不是 xabxa$ 的前缀了,这样对应的节点肯定是在 xa 之后接上 $ 和 bxa$。
如果有 suffix tree 如何做 string matching 呢?
- 首先对待搜索字符串 T 进行处理建立 suffix tree,这个可以在
时间内搞定(后面会介绍做法);
- 长度为 n 的搜索串 P 在 T 中当且仅当它出现在 T 的某个 suffix 中,因此,我们只需要看看 P 是不是出现在某个 root path 就行了,如果没有表示 P 没有被找到,如果有则所有共享这个 prefix 的 path 都是搜索结果;
- 由于每个 root path 都有对应 suffix 的编号,我们就能知道 P 出现在 T 的什么位置了;
这样我们可以在 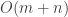
那么如何建立一个 suffix tree 呢?比较土的想法就是通过 recursion,对于长度为 m 的字符串,我们去掉第一个字符,把问题规约成 m – 1 长度的字符串。我们知道:
- 如果长度为 1,获得 suffix tree 就是单边,两个节点(root 和一个 leaf)的树;
- 如果我们有了一个 m – 1 字符串对应的 suffix tree,新增加一个字符,这会新增加一种 suffix:
- 如果该字符不是任何 m – 1 个 后缀的 prefix(也就是说没出现在后面 m-1 个字符中),那很简单,直接增加一个 node,对应的边是整个新的字符串就行了;否则
- 我们将整个新的字符串沿着 m-1 个字符的 tree 走下去,因为第一个字符出现过,所以肯定能走下去,一直碰到某个无法匹配的位置,这时我们把对应边上的 label 截断,放置一个新的 internal node,然后将原先剩余的部分连接到这个 internal node 到原先 child node 的边上(这部分保持原先的 path 不变);产生一个新的 leaf node,将新的 internal node 与之相连,对应边是长度为 m 的字符串剩余的部分。
但是这个算法的时间复杂度为 
- 如果首字母不匹配,我们就直接创建新的 leaf,并与 root 连接;
- 如果匹配,则找到最长的匹配,然后截断这个 edge 上的 label,创建新的 internal node:将新的 internal node 与原先的子 node 连接,边上为截断后剩余的 label;创建新的 child node,将此时 suffix 对应剩余部分作为连接 internel node 到此 child node 的边的 label;
实现的时候后者可以两种情况写在一起:计算 share 字串(prefix)的长度,在 share 部分创建一个新的 internal node(如果需要的话),后面的产生新的 leaf 都是一样的。
如果想把这个算法 improve 到线性,我们需要 Ukkonen’s algorithm(其他的选择有 Weiner’s algorithm,McCreight’s algorithm)。
换一个角度,suffix tree 本质上就是一个将 suffix 用 trie 结构存储的索引,这个索引对很多问题都有帮助。因此实现的时候可能需要实现一个 generic 的 trie,然后在此基础上获得 suffix tree。不知道这个东西(以上各个算法)是否设计成为一个 generic algorithm 存在还是得设计成别的什么。trie 作为一个 container 或者 underlying 数据结构。
另外一种类似的数据结构是所谓 suffix array,简单的说我们可以将所有的 suffix 组成一个数组,sort 一下(按照字典序),我们为每个 suffix 保持它的编号,以及与前一个 suffix 共同的元素个数。对应也有一些更加快捷的生成方式,这是依赖 suffix tree 获得的。
搜了一下,似乎 boost 里面很早就有人试图引入 suffix tree,但是没见到后文了。网上能找到的一些实现如比较早的,C 的版本感觉局限性比较大(libstree 与这个),有两个 C++ 的但是估计不是利用 template 写的(SuDS 的 cst 与这个)。
——————
And Abram said to Lot, Let there be no strife, I pray you, between me and you, and between my herdsmen and your herdsmen; for we be brothers.
