这里我们集中讨论一下 collaborative filtering 中矩阵分解相关的工作。这部分工作的核心就是如何进行矩阵的分解,能够尽可能的逼近原有 rating matrix 中含有 rating 的部分。为了一致性,我们假定 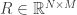



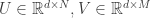



下面就是建立一个合理 loss function,这可以从“噪声模型”来下手,比如常见的就是使用 Gaussian noise,这时的 MLE 等价于(简单起见,先考虑一个没有 bias 的模型)

所谓的 ALS(alternating least square)就是先固定一边,优化另一边的策略,求导之后容易获得下面的策略:
- 固 定
,更新
,其中
是第
个用户打过分的 item 对应在
,后者是一个列向量。
- 固定
,更新
,这里是对偶的关系;
为了把这些东西写得更清楚一些,我们使用两个辅助的符号 
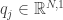




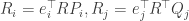
这样可以“简化”更新规则,


很不幸的是似乎每个 user/item 的低维表示可以解耦(即 
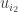
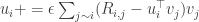

但是这样做是和 ALS 类似的。为了更好的优化,实际我们应该针对“耦合”来做,每次选择一个 rating 进行 optimization,这时我们需要更新的是 
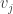
实现 ALS 的 map/reduce 策略比较容易,我们给一个比较傻的版本,每条 record 包含五项,user,item,
- 如果 user 为 key,reducer 拿到每个 user 对应的 item 列表,这样就能更新各自的
- 如果 item 为 key,reducer 拿到每个 item 对应的 user 列表,这样就能更新各自的
如果实现的 SGD 则比较麻烦,但是有一点比较有意思,如果前后两次更新的两个 rating,

对一个更复杂一些的带有 bias 的 model 来说,我们一般会计算所有 rating 的均值 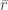
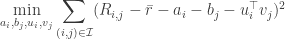
这时我们更新的策略会稍有不同(主要是增加的项)

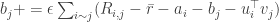
值得注意的是为了避免造成过拟合,往往我们会为 
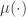
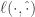

特别的使用 probabilistic model 的时候往往 link function 与 loss function 有一定的 connection,整个更新的步骤有望进一步化简。最常见的一种方式就是使用 exponential family,比如以上例子我们可以认为选取的模型是 
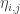

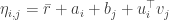


使用这类 probabilistic model 我们就能很容易的换个角度理解 regularization,对以上 frequentist’s model,我们为参数选择 Gaussian 的先验,那么对应的 prior 新增上去对新的模型的 MAP 估计就正好是前面给出的带
有了这样一些宏观上的认识之后我们来看看一些文献上的处理方式。
我看到的第一篇这方面的 paper 是所谓的 M3F(最早发在 NIPS 04),直观上来说这个 model 的想法就是避免使用 MSE 而是使用 SVM 的 Hinge loss 来刻画差异性,直观上来说就是小错不算错,错大了就不好(这是对 binary 的情形做的),对应的求解却使用了 SDP(巨慢吧…)。之后的一个改进发表在 ICML 上,我们这里简单的介绍其 idea,假定 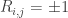


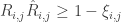
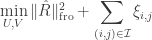
除了通过某种邪恶的方式(SDP)求解以外,我们可以考虑将 Hinge loss 用 smoothed Hinge loss 替代(比如使用前面的 logistic regression 对应的形式,这就是 ICML 那篇文章的主要思路),这样就可以使用 SGD 类似的方式(比如文中采用了 CG)进行求解了。这部分的工作主要是来自 Nathan Srebro 等人,Nathan 似乎是 Hinton 那里出来的。
Hinton 的另一个学生 Ruslan 的一部分工作在于使用 probabilistic model 对 matrix factorization 建模,最早的文章可能是发表在 NIPS 2008 上,除了以上我们讨论过的概率模型以外,他们还讨论了一个所谓的 constrained probabilistic matrix factorization,我们知道出现问题较大的用户主要是 rating 给予的较少,根据我们的 Bayesian 解决方案会回退到接近先验的情形,但是不管什么用户都会回退到一个先验,这很可能是不大正确的,一种可能就是我们把先验换成从 
当然 Ruslan 作为 Hinton 的学生更是对 deep belief nets 的组成元件 RBM 深有心得,更早的一份发表在 ICML 07 上工作就是希望通过 RBM 实现类似的工作。RBM 是一个 PoE,也是一个 Markov random field,还是一个 generative model。他们认为 RBM 的 visible layer 就是用户的 rating,而这些 rating 是由 hidden layer 生成出来的,问题是现在的观测(visible)还是 incomplete 的。比如说我们的 rating 是 1-5 离散的,我们就可以在 visible layer 使用 multinomial distribution,而在 hidden layer 使用 Bernoulli,这样对应的 energy function 我们可以写出来,从而能够获得对应的条件概率以及 free energy,此后就是 contrastive divergence 这个套路了。不过这个模型比较奇怪的是具有 

Nathan 和 Ruslan 后来还合作发表了一篇 NIPS 11 的文章,但是似乎是对非均匀采样情况下 Nathan 同志原先模型的一种修正。这里就算了。
下面谈谈工业界的一些 paper。比较有名的可能就是 Yahoo! Research/Labs 的一种试图解决 cold start 问题的方法(见 SIGKDD 09)。我们知道 matrix factorization 是一个 non-parametric model,它的主要问题是 code start,在没有任何 feature 出现的情况下我们无法给 user/item 进行任何推荐。相对的,我们可以使用 logistic regression/ordinal logistic regression 获得一个完全 parametric 的 model,如果我们拥有 user/item 和 user
——————
And I will fetch a morsel of bread, and comfort you your hearts; after that you shall pass on: for therefore are you come to your servant. And they said, So do, as you have said.
